Pose Estimation 指标
关键点检测的指标主要是OKS和PCK。其中OKS是现在的常用指标,PCK主要用在MPII等较老的数据集上,从OKS还衍生出AP和AR两个指标。
OKS (Object Keypoint Similarity)
$$
OKS_p = \frac{\sum_i\exp(\frac{-d^2_{pi}}{2S^2_p\sigma^2_i})\delta(v_{pi}=1)}{\sum_i\delta(v_{pi}=1)}
$$
$p$ 表示person id
$i$表示 keypoint id
$d_{pi}$表示预测的关节点和标注的关节点的欧氏距离
$S_p$ 表示尺度缩放因子,$S_p=\sqrt{(x_2-x_1)(y_2-y_1)}$
$\sigma_i$ 表示第$i$个骨骼点的归一化因子,对数据集中所有groundtruth计算的标准差而得到的,反映出当前骨骼点标注时候的标准差, $\sigma_i$越大则越难标注
$v_{pi}$表示关节点是否可见
1 | def compute_oks(dts, gts): |
OKS 矩阵
对于多人姿态估计,若gt中M个人,预测了N个人,计算两两之间的OKS构成$M\times N$矩阵,最后选择每个gt的人中最大的OKS值作为结果。
PCK (Percentage of Correct Keypoints)
$$
PCK_p^i=\frac{\sum_p\delta(\frac{d_{pi}}{d_{p}^{def}}\le T_i)}{\sum_p1}
$$
$p$ 表示person id
$i$表示 keypoint id
$d_{pi}$表示预测的关节点和标注的关节点的欧氏距离
$d_{p}^{def}$ 表示尺度缩放因子,对于FLIC使用的是躯干直径(左肩到左臀或右肩到左臀),对于MPII用的是头部对角线的长度(PCKh)
$T_i$ 表示第$i$个骨骼点的阈值
1 | def compute_pck_pckh(dt_kpts,gt_kpts,refer_kpts): |
PCK现在用的不多,主要用的是OKS
AP(Average Precision)& AR(Average Recall)
AP和AR都是针对整个数据集而言的。在算Precision或者Recall之前,必然先要对关键点检测结果进行排序,很多文章都没有明确这里排序的依据是什么。从实现上来看,是根据人检测框的置信度高低进行排序的。
在计算AP和AR之前,先要画出$OKS=k$下的PR曲线。先对每个检测结果排序,然后计算从头到第k个结果时的Precision和Recall,就能画出PR曲线了,算出曲线下面积,在COCO中用的是11点采样法。Precision和Recall的计算方式如下所示:
$$
P=\frac{TP}{TP+FP}
$$
$$
R=\frac{TP}{TP+FN}
$$
对于多人关键点检测的任务,首先要做的是将检测到的结果dt和gt做匹配($OKS \gt k$则为一对匹配,每个dt会和OKS最大的相匹配),那么就可能会出现有的dt没有与之相匹配的gt。从代码中可知,COCO中将TP定义为有匹配并且匹配到的不是ignore的gt,FP的定义为没有匹配的gt,$TP+FN$其实就是所有的gt个数(比如标注了100个instance,那么$TP+FN=100$)。
$OKS=k$下,$AP^{OKS=k}$就是此时采样后的Precision均值。$AP=\frac{1}{10}\sum_{k\in0.5:0.05:0.95}{AP^{OKS=k}}$,$AR$同理。
关于COCO上各个指标的具体定义可以参考下图:
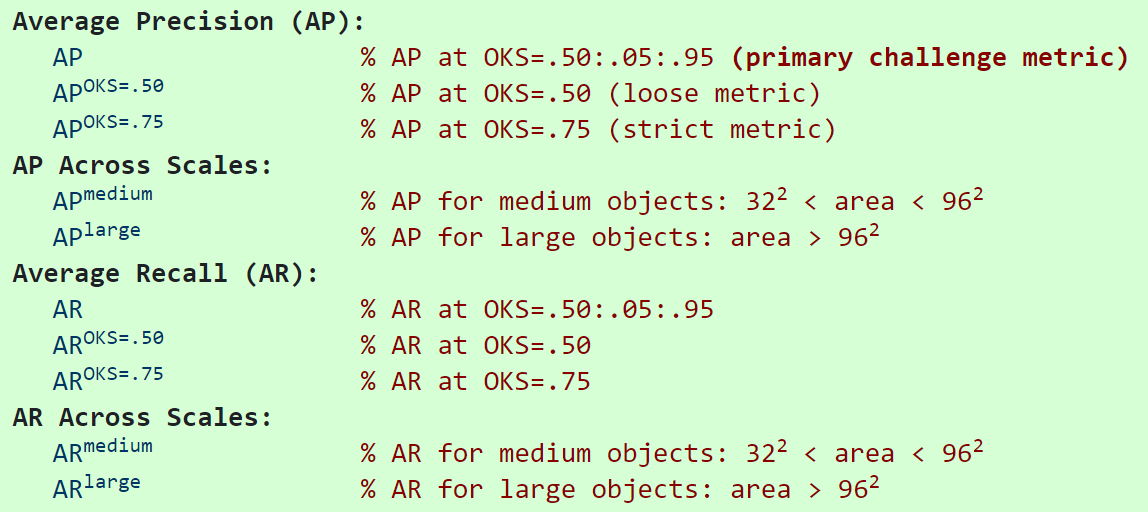
人体姿态估计-评价指标(一)_ZXF_1991的博客-CSDN博客
目标检测中的mAP是什么含义? - 知乎
mAP for Object Detection